Workers
Introduction
Workers are the main building block in actionETL, and the different types of workers are configured and combined into a Worker System to do the required processing of files, database access, rows, etc.
Note
- A worker is an instance of any class that, directly or indirectly, inherits from WorkerBase<TDerived>
- A worker system is an instance of any class that, directly or indirectly, inherits from WorkerSystemBase<TDerived>. The commonly used one is WorkerSystem. A worker system can have zero or more workers as its descendants.
- Both workers and worker systems inherit from WorkerParent, i.e. they can both have workers as children
actionETL comes with a large number of workers (see below), and also makes it easy to create new Custom Workers by:
- Composing existing workers, i.e. encapsulating one or more workers to create a new worker
- Deriving a new worker from an existing one, and add the required custom functionality
Furthermore, a number of the out-of-box workers provide the bulk of the implementation, but allow you to provide just your specific functionality via a callback (e.g. a code snippet via an Action or a Func<TResult>). This approach makes the workers very flexible and easy to adapt to different requirements, e.g.:
- In the dataflow
*JoinMerge*workers, equi joins (i.e. just using one or more equal signs:A.Id = B.Id) can be specified by simply listing the column names. You can however instead specify the join condition as a callback, allowing non-equi joins (A.Id = B.Id && A.StartDate > B.StartDate && A.Status <> 'D'). - Columns to sort on in
SortTransformcan be specified just by listing their name; for more complicated sort criteria a callback can be provided inline that calculates an ordering value from the column values, removing the need to precalculate it in a separate worker, or to add it to the data rows.
Hierarchy
Workers are created and executed in a parent-child hierarchy. A workers system instance is always at the root of the hierarchy, with an arbitrary number of descendant workers and levels. In this example:
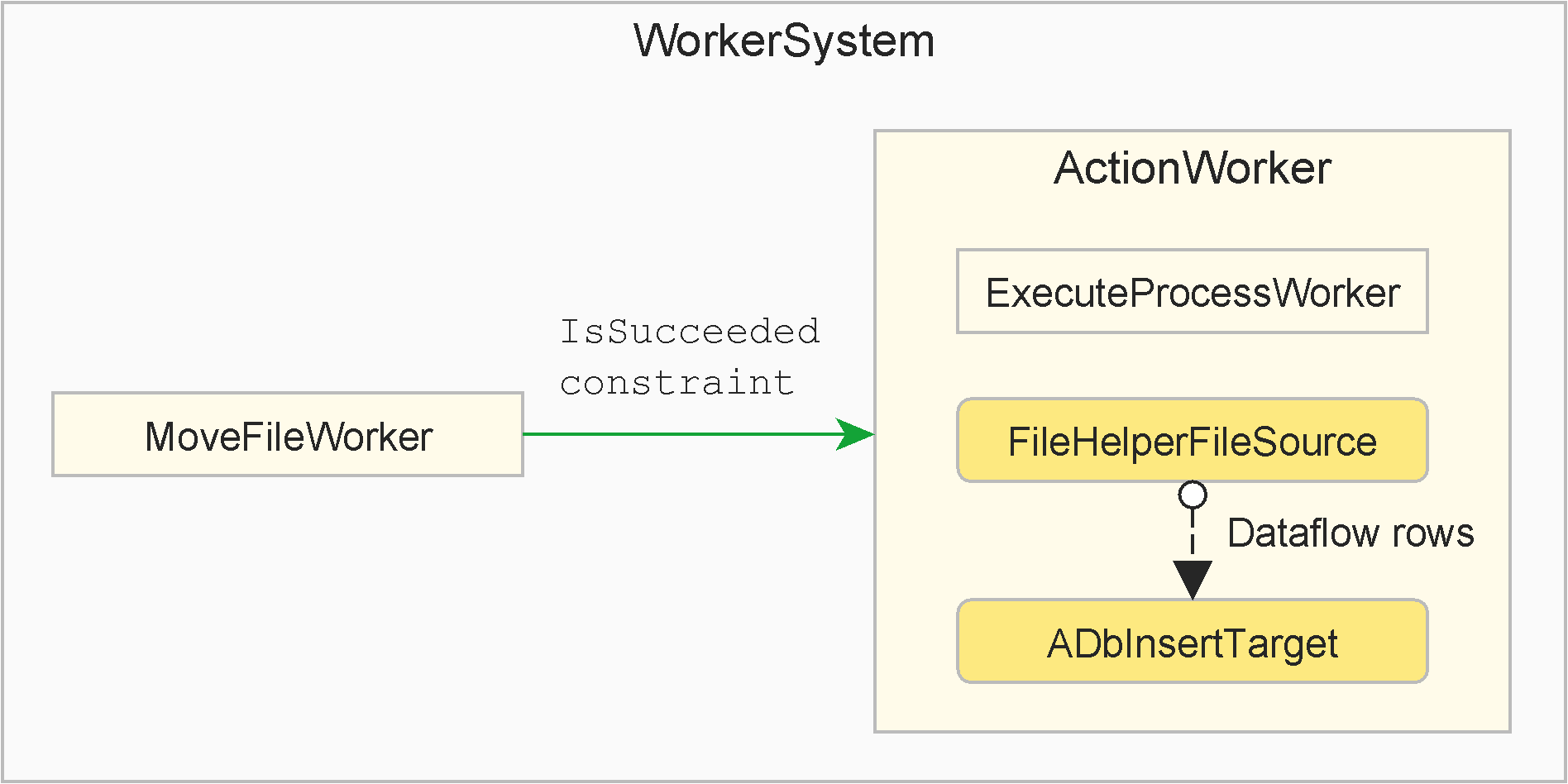
- The six rectangles represent one worker system instance, and five distinct worker instances
- Execution order and duration is:
WorkerSystem, until none of its children are running or can be startedMoveFileWorkerActionWorker(until it's three children have completed)ExecuteProcessWorker,DbDataReaderSourceandDbInsertTargetin parallel
Please see Adding and Grouping Workers and Worker Execution for more details.
Data Ports
Workers can have high speed data ports for sending many millions of rows of data per second between workers, creating a dataflow. A worker is called a:
- Dataflow worker if it has one or more data ports (a.k.a. dataflow components in some ETL tools)
- Non-dataflow worker if it does not have data ports (a.k.a. control flow tasks in some ETL tools)
Note
In actionETL there is no fundamental difference between the two types, and they can be mixed and matched as needed, e.g.:
- A single worker can be created to perform both dataflow and non-dataflow tasks
- Dataflow workers and non-dataflow workers can contain both dataflow and non-dataflow child workers
- Worker start constraints can be set between dataflow and non-dataflow workers
These capabilities provide great flexibility in how applications are designed, and also remove the need to create multiple "dataflows" just to intersperse "control flow tasks" between them. This reduces both complexity and the need for temporarily staging data to disk.
Please see Dataflow for more details.
Naming
Workers can be further categorized via their names, and it is best practice to also name custom workers using these conventions:
| Worker Name | Description |
|---|---|
| *Action* | Library user provides the bulk of the logic via a callback (often Action or Func<TResult> lambda), e.g. ActionWorker. "Action" should come immediately before "Worker", "Source", "Transform", or "Target" in the worker name. |
| Adb* | Workers accessing an SQL database using the Adb* group of classes, e.g. AdbExecuteScalarWorker<TResult>. Note that provider-specific workers also have their dedicated prefix, e.g. AdbSqlClient in AdbSqlClientBulkInsertTarget. |
| *Base | Workers that must be extended by being inherited from, e.g. ActionWorker inherits from ActionWorkerBase<TDerived> |
| *Row* | Dataflow worker that processes a single row at a time, e.g. RowActionTarget<TInput> |
| *Rows* | Dataflow worker that processes multiple rows at a time, e.g. RowsTargetBase<TDerived, TInput> |
| *Source or *SourceBase | Dataflow sources have output ports but no input ports, e.g. EnumerableSource<TOutput> |
| *Target or *TargetBase | Dataflow targets have input ports but no regular data output ports (they might have error output ports), e.g. AdbInsertTarget<TInputError> |
| *Transform or *TransformBase | Dataflow transforms have both input and regular data output ports, e.g. SortTransform<TInputOutput> |
| *Worker or *WorkerBase | Non-dataflow workers, e.g. CopyFileWorker |
List of Workers
The following articles list all out of box workers:
- Non-Dataflow Workers (a.k.a. control flow workers)
- Dataflow:
- Database Workers (also included in above lists)