Dataflow
Dataflow workers are ordinary workers, but with input and/or output ports added for very
quickly sending data rows between ETL workers. Each row is a class instance. The dataflow is
in-memory and in-process. Capabilities include:
- Quickly moving, processing, aggregating, and combining data rows, to and from different types of data sources and targets (a.k.a. destinations), such as flat files, databases etc.
- Decomposing the required processing into small, manageable chunks, that together solve a larger problem
- Mixing and matching dataflow workers with non-dataflow workers, without splitting into separate dataflows
- Supporting all data types as dataflow columns inside a dataflow row
- Reusing and composing dataflow schemas that group dataflow columns, which minimizes schema coding and maintenance effort
- Encapsulating multiple dataflow and non-dataflow workers into a single new reusable dataflow worker, that can in turn be combined with other workers to solve larger problems
- High flexibility where sort criteria, join criteria etc. can be specified either by listing columns, or by providing a callback function
- Fluent coding style factory methods for transform and target workers, to in most cases only specify each dataflow row type once, usually on the source worker, and having the downstream transforms and targets automatically derive the row types (at compile time). This reduces typing and code maintenance effort.
- Very high performance:
- Stream processing and flow control for reduced memory requirements
- Workers execute in parallel
- Very fast port to port links
- View dataflow rows in flight when debugging
The dataflow workers are categorized by what data ports they have:
- A source worker (list) has at least one data output port, but no input ports. It typically extracts data from an external source, e.g. a database or a file, and sends data rows to its output port(s). It can also generate data rows from scratch, e.g. a random number generator.
- A transform worker (list) has both input and data output ports. It consumes and processes the input data rows, and outputs the same (modified or unmodified) rows it received, and/or generates new rows to output. The output ports can have a different schema vs. the input ports.
- A target worker (list) has at least one input port, but no data output ports. It consumes the input data rows, and typically loads them to an external target, such as a database, a file, a .NET collection etc.
When dataflow workers are started, all data output ports must be linked to input ports, and vice versa. Furthermore, each output port can only be linked to a single input port, and vice versa. A single worker can however have multiple input ports, and multiple output ports.
Apart from the above data ports, dataflow workers can optionally also have one or more error output ports. They work similarly to data output ports, except that linking to an input port is optional, and they are only used for redirecting rejected rows. E.g.:
- A source worker extracting a CSV file might encounter a badly formatted row, and reject the bad CSV row to its error output port
- A random number generator source would on the other hand never generate a bad row, and would therefore not have any error output ports configured
Please see Dataflow Row Errors for further details.
A worker can have any number of input, output, and error output ports, as long as the rules on linking ports are followed.
Important
Ports can only be linked between workers that have the same parent.
Note however that it is possible to pass rows between workers that have different parents (without 'linking' their ports directly) by using the PortPassThroughSource<TOutput> and PortPassThroughTarget<TInputOutput> workers. This is mainly used for passing rows between a parent and a child worker when encapsulating dataflow workers, see Custom Dataflow Workers for details.
Example
Ports are instances of OutputPort<TOutput>, ErrorOutputPort<TError> and InputPort<TInput>, and are surfaced as properties on the worker:
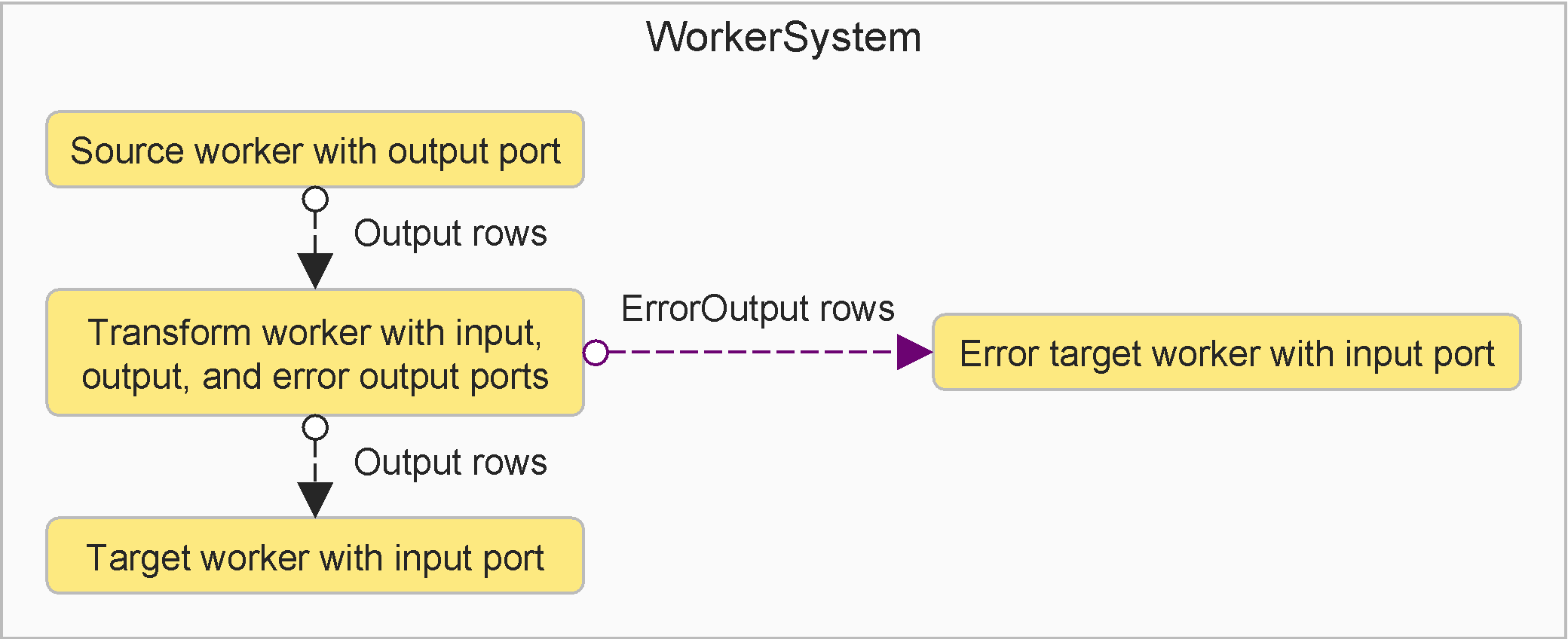
- The source sends data rows to the transform.
- The transform consumes input data from the source. Incorrect rows are rejected to the error target, and will also be logged. Remaining data rows are sent to the target.
- The error target and the target consume incoming rows, e.g. storing them to a file or a database.
Below is an example of an ETL dataflow that matches the above graph. It demonstrates generating, validating, and storing dataflow rows into CSV files.
Note how the transform and targets are created from the factory methods on an upstream
output port Link property. This not only links them to the upstream port, but also
provides the worker parent instance and row type, so these don't need to be specified
in the method call.
With multiple targets for one upstream transform, we store the upstream worker references in variables, so that we can use the transform reference multiple times.
using actionETL;
using actionETL.FileHelper;
using FileHelpers;
using System.IO;
using System.Linq;
[DelimitedRecord(",")] // Needed for CSV file
public class MyRow
{
public int MyId { get; set; }
public string MyString { get; set; }
}
// ...
new WorkerSystem()
.Root(ws =>
{
// Generate 15 rows
var source = new EnumerableSource<MyRow>(ws, "Source"
, Enumerable.Range(0, 15)
.Select(id => new MyRow { MyId = id, MyString = "Hello " + id })
);
// Reject string longer than 7 to error output port
var transform = source.Output.Link
.RowActionTransform1("Transform", row => row.MyString.Length > 7
? TransformRowTreatment.Reject : TransformRowTreatment.Send);
// Store any error rows to an error CSV file
transform.ErrorOutput.Link
.FileHelperFileTarget("Error Target", "MyErrors.csv");
// Store data rows to a CSV file
transform.Output.Link
.FileHelperFileTarget("Target", "MyData.csv");
})
.Start()
.ThrowOnFailure();
Note
- Circular dataflows (where the output of a downstream worker is linked to the input of an upstream worker, or to itself) are not allowed.
- See Worker Execution for details on dataflow execution order.
Row Flow Control
The dataflow uses back pressure to limit the amount of rows in flight and memory used at any one time. Workers (and users if reading/writing ports directly) must adhere to the following rules (or an error will be raised):
Important
- Do not send more rows to a data output port than there is row demand present on the port
- Do not take more rows from an input port than there are rows available on the port
Individual workers and their ports provide the tools that make it easy to follow these rules.
Ports
All workers have the properties Inputs, Outputs, and ErrorOutputs that enumerate their input, output, and error output ports, respectively. These properties do however return 'untyped' (OutputPortBase and InputPort) ports, i.e. they can be used for checking port status and row counts, but cannot be used to send or receive actual rows.
Dataflow workers therefore adds members that allow the developer easy access to their specific typed ports:
- Workers with a single input port add a property named "Input", see e.g. Input
- Workers with multiple input ports of different types add properties prefixed with "Input", see e.g. LeftInput and RightInput
The same approach is used for output and error output ports, but naming/prefixing/suffixing them with "Output" and "ErrorOutput" instead.
Furthermore, workers with multiple input ports of the same type add a TypedInputs property,
see Adding Ports and e.g.
TypedInputs. The same approach is used for output ports.
Note
All input ports on a single worker must have unique names. The same goes for the output ports, and the error output ports, respectively.
Port Locator
The port Locator property describes where in the ETL worker hierarchy the port resides.
This is visible in the logging output, and is also used when setting a configuration
value on a specific port by supplying an applyTo value to e.g.
SetValue(String, String, Int64).
The port Locator string consists of its worker Locator string, with a port
specific string appended. E.g. for a transform worker "Process" directly under the
worker system "Root", port locators would be:
| Port | Locator |
|---|---|
| "LeftInput" input port | "/Root/Process.Inputs[LeftInput]" |
| "Output" output port | "/Root/Process.Outputs[Output]" |
| "Reject" error output port | "/Root/Process.ErrorOutputs[Reject]" |
Linking Ports
Two linked ports must have the exact same row type. This is enforced at compile time, which guards against connecting incompatible ports.
The most common and natural way to create dataflow workers is in the order the rows flows, i.e. source > transform > target.
Workers with input ports (i.e. transforms and targets) are then created and linked using factory methods on the upstream Link property, which in most cases avoids having to repeat the row type parameters, which in turn reduces typing and code maintenance effort.
When each upstream worker is linked to a single downstream worker, we can also use a fluent coding style to avoid storing the worker references in variables, and further minimize typing - this example selects the last input row, if any:
// using actionETL;
// using System;
// using System.Collections.Generic;
private sealed class Row
{
public int Category;
public int Metric;
}
private readonly Row[] _sampleData = new Row[]
{
new Row { Category = 1, Metric = 2 }
, new Row { Category = 1, Metric = 2 }
, new Row { Category = 1, Metric = 5 }
, new Row { Category = 2, Metric = 10 }
};
public WorkerSystem RunExample()
{
var workerSystem = new WorkerSystem()
.Root(ws =>
{
var source = new EnumerableSource<Row>(ws, "Source", _sampleData)
.Output.Link.AggregateTransform1(
"Transform"
, RowAggregationFunction.Last
, g => g.Name(nameof(Row.Category)) // Group by column [Category]
)
// Receives two rows:
// { Category = 1, Metric = 5 }
// { Category = 2, Metric = 10 }
.Output.Link.CollectionTarget();
});
workerSystem.Start().ThrowOnFailure();
return workerSystem;
}
Note
Sometimes the downstream worker needs to be created before the upstream worker
port is available.
In these rare cases, create the downstream worker from the parent worker, e.g.
parent.GetDownstreamFactory<MyClass>.CollectionTarget("MyName4" /*,...*/),
as in this
example.
To link ports explicitly, use
LinkTo(InputPort<TOutput>)
or LinkFrom(OutputPortBase<TInput>).
Changing Row Schema
Many ETL transforms have the same input and output port types/schema, e.g. SortTransform<TInputOutput> and ActionTransform<TInputOutputError>.
Other ETL transforms support changing the row schema, i.e. having a different output vs. input schema, see e.g. ActionTransform<TInputError, TOutput> and InnerJoinMergeSortedTransform<TLeftInput, TRightInput, TOutput>.
As an alternative to changing the row schema, one can also add all required columns in the upstream source or transform, and ignore unused columns until they are needed in downstream transform or target workers.